
Finish. That. Idiom. NLP exercise.
Given this dataset
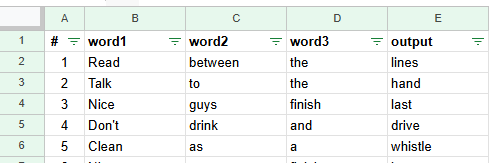
We will need to predict the next word when given the first 3 words
Why?
Because it was an assignment for my Discrete Mathmatics class.
Data Prep
To make this work, we need to encode each word into a format our neural network can understand. This is done through one-hot encoding, where each unique word is represented by a binary vector. For instance, the word "Read" might be encoded as [1, 0, 0, ...] while another word like "hand" might be [0, 1, 0, ...]. This encoding is essential for numerical processing in machine learning.
It's a pretty simple function:
def one_hot_encode(word, vocabulary):
vector = np.zeros(len(vocabulary))
if word in vocabulary:
vector[vocabulary[word]] = 1
return vectorWe use this function to build to list, one that contains a vector for each of the first 3 words, and another list for that contains the vectors for the last word. We will use these later for training. You can see this code:
feature_train = []
output_train = []
for line in d:
line = line.split("\t")
input = [line[1], line[2], line[3]]
output = line[4]
feature_train.append(process_input(input, vocabulary))
output_train.append(one_hot_encode(output, vocabulary))Tensorflow
We created a neural network with two hidden layers (64 and 32 neurons). This setup strikes a balance between capturing enough complexity to recognize word patterns and keeping things efficient. The next layer uses a softmax activation to produce probabilities for each word in our vocabulary.
model = tf.keras.Sequential([
layers.Dense(64, input_shape=(input_size,), activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(output_size, activation='softmax')
])We followed this up by trainig using the feature_train and output_train lists.
Predicting
To predict the next word, we pass the three input words, encoded in the same one-hot format, into the model. The model outputs a probability for each word in the vocabulary, and the word with the highest probability becomes our predicted fourth word.
For example, if the input is ['Read', 'between', 'the'], the model might predict the next word as lines. The predict_next_word function handles this by using the model’s output probabilities to select the most likely word.
def predict_next_word(model, words, vocabulary):
X = process_input(words, vocabulary)
X = np.expand_dims(X, axis=0)
prediction = model.predict(X)
predicted_index = np.argmax(prediction)
reverse_vocab = {v: k for k, v in vocabulary.items()}
return reverse_vocab[predicted_index]
# user input will be the first 3 word and output will be the final word
words = ['Read', 'between', 'the']
print("Idiom:", " ".join(words),"...")
final_word = predict_next_word(model, words, vocabulary)
print("Prediction:", final_word)